✅ 메모리 계층성
`빠른 저장 장치`와 `용량이 큰 저장 장치`는 다음과 같은 이유로 동시에 만족하기 어렵다.
- CPU와 가장 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 작고 가격이 비싸다.
이러한 물리적 제약 때문에 컴퓨터 시스템은 다양한 저장 장치를 함께 사용한다.
그리고 이 저장 장치들은 'CPU에 얼마나 가까운가'를 기준으로 다음과 같이 계층적으로 표현할 수 있다.

- 위 계층일수록 CPU와 가깝고, 용량은 작고, 빠름
- 아래 계층일수록 CPU와 멀고, 용량은 크고, 느림
✅ 캐시 메모리란?
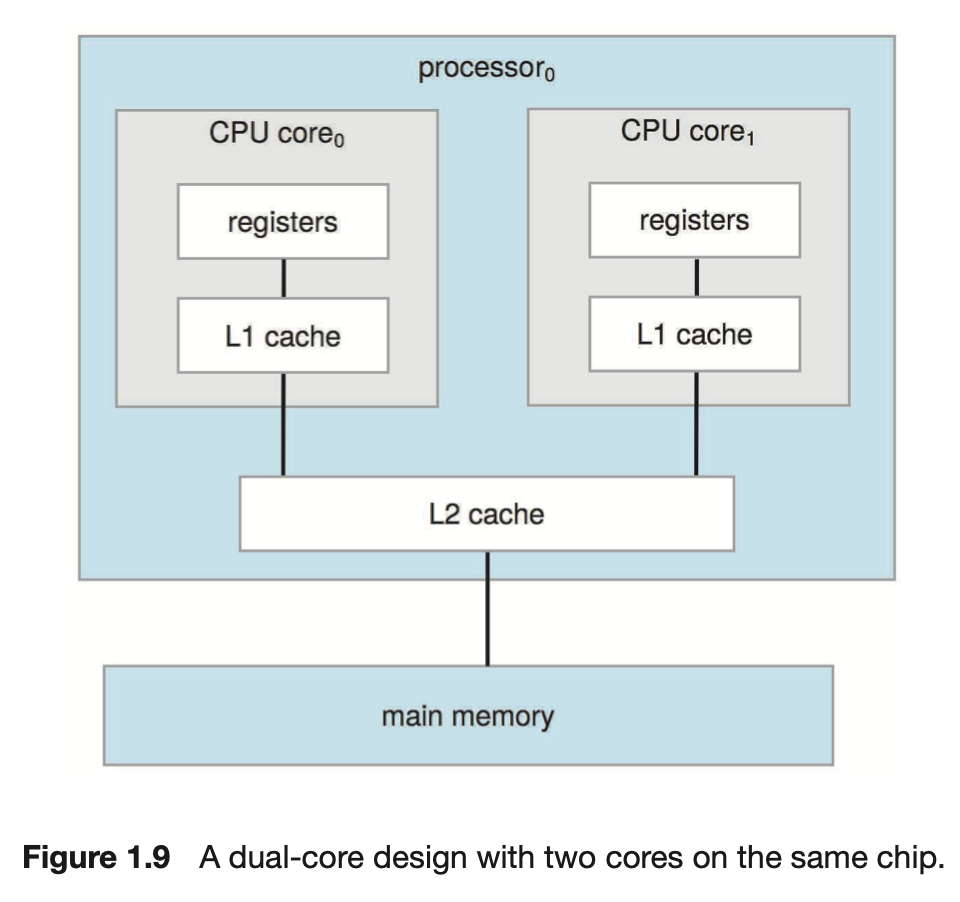
: CPU와 메인 메모리(RAM) 사이에 위치하는 메모리
CPU는 메모리에 저장된 데이터를 빈번하게 사용하지만 CPU가 메모리에 접근하는 시간은 CPU의 연산속도보다 느리다.
따라서 이를 극복하기 위해 등장한 저장 장치가 캐시 메모리이다.
캐시는 용량이 매우 작다.
따라서 컴퓨터는 여러 개의 캐시 메모리를 사용한다.
그리고 이 캐시 메모리들은 다시 CPU와 가까운 순서대로 계층을 구성한다.
| 구분 | L1 캐시 | L2 캐시 | L3 캐시 |
| 위치 | CPU 코어 내부 | CPU 코어 내부 또는 근처 | 여러 코어가 공유, CPU 외부에 가까움 |
| 속도 | 가장 빠름 | L1보다 느림 | L2보다 느림 |
| 용량 | 가장 작음 | 중간 | 가장 큼 |
| 가격 | 가장 비쌈 | 중간 | 상대적으로 저렴 |
| 분리 여부 | 보통 I-Cache, D-Cache로 분리 | 통합형(L1 백업 역할) | 통합형 |
| 용도 | 가장 자주 쓰이는 명령어/데이터 캐싱 | L1 캐시 미스 시 백업 | 멀티코어 간 데이터 공유 및 백업 |
L1 캐시는 조금이라도 접근 속도를 바르게 만들기 위해 명령어만을 저장하는 L1l 캐시와, 데이터만을 저장하는 L1D 캐시로 분리한다.
L1과 L2 캐시만으로도 다음과 같이 구성할 수 있다.
✅ 캐싱 라인
: 캐시에 저장되는 데이터 단위
캐시에 데이터를 저장할 때는 묶음 자료구조인 캐싱 라인(Caching Line)을 사용한다.
즉, 메모리부터 캐시로 데이터를 가져올 때, 캐싱 라인을 기준으로 가져온다는 의미이다.
- 일반적으로 여러 바이트로 구성됨 ex) 32 byte, 64 byte
- CPU가 특정 주소의 데이터를 접근하려고 한다면, 해당 주소를 포함하는 전체 캐시 라인이 캐시로 가져와짐
✅ 캐시 매핑 전략
메모리에서 데이터를 가져와 캐시에 mapping 하는 방식에는 다음과 같은 세 가지 방식이 존재한다.
| Direct Mapping | 하나의 메모리 블록은 캐시의 특정 한 줄에만 저장 가능 |
| Fully Associative | 어떤 블록이든 캐시 어디에나 저장 가능 (유연하지만 느림) |
| Set Associative | 여러 개의 줄(Set) 중 하나에 저장 가능 (속도와 유연성의 균형) |
✅ 캐시 정책
: 캐시에 어떤 데이터를 불러오고, 유지하고, 버릴지를 결정
📍 교체 정책
: 캐시가 꽉 찼을 때, 어떤 캐시 라인을 교체할지를 결정하는 알고리즘
- LRU (Least Recently Used): 가장 오래 사용하지 않은 캐시 라인 제거
- FIFO (First In First Out): 가장 먼저 캐시에 올라온 라인 제거
- Random: 무작위로 캐시 라인 제거
📍 쓰기 정책
: CPU가 데이터를 쓸 때, 해당 데이터의 캐시와 주기억장치의 동기화 방법을 결정하는 정책
- Write-through: 데이터를 캐시와 메인 메모리에 동시에 기록
- Write-back: 캐시에만 먼저 데이터를 기록하고, 특정 조건에서 메인 메모리 업데이
✅ 데이터의 지역성 (Locality)
: 기억 장치 내의 정보를 한순간에 특정 부분을 집중적으로 참조하는 특성
작은 용량의 캐시 메모리에 모든 데이터를 넣을 순 없으므로, 어떤 데이터를 넣을 것인지는 매우 중요하다.
이에 따라 적중율(hit ratio)이 달라지기 때문이다.
그리고 이 적중율을 극대화하기 위해서는 데이터 지역성 원리를 이용한다.
지역성은 시간 지역성과 공간 지역성으로 나눌 수 있다.
- 시간 지역성(temporal locality): 최근에 참조된 주소의 내용은 곧 다시 참조되는 특성
- ex) 반복문 내부 변수
- 공간 지역성(spatial locality): 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
- ex) 배열
캐시 메모리에 찾는 데이터가 존재한 경우를 Cache Hit라고 한다.
그리고 캐시가 히트되는 비율은 Cache Hit Ratio라고 한다.
- Cach Hit Ratio = Cache Hit 횟수 / (Cache Hit 횟수 + Cach Miss 횟수)
보통 컴퓨터의 Cache Hit Ratio는 85~95% 이상이다.
✅ 캐시 간의 동기화
여러 캐시가 동일한 메모리에 대한 데이터를 동시에 가질 때, 그 데이터의 일관성을 유지해야 한다.
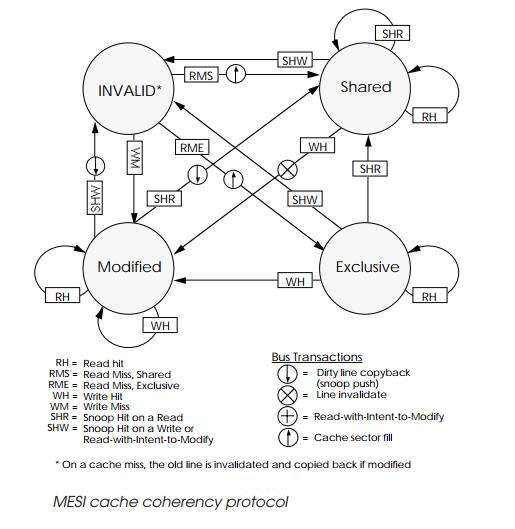
대표적인 방법으로는 MESI 프로토콜이 있다.
📍 MESI 프로토콜
해당 프로토콜에는 다음 4가지 상태가 사용된다.
- Modified: 변경됨, 메모리와 불일치
- Exclusive: 메모리와 일치, 하나의 캐시에만 존재
- Shared: 여러 캐시에 존재, 메모리와 일치
- Invalid: 유효하지 않음, 다시 가져와야 함
그리고 읽기/쓰기 연산에서 각 상태에 따라 다음과 같은 동작이 수행된다.
✨ 추가 질문
[ 캐시의 지역성을 기반으로, 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이? ]
공간 지역성을 기준으로 생각해 보자.
arr [i][j]가 있을 때
- 가로 방향: j가 먼저 증가
=> 메모리에 연속적으로 저장된 데이터에 차례대로 접근하므로 지역성이 높아 cahe hit 가능성이 높음
- 세로 방향: i가 먼저 증가
=> 메모리 상 불연속적인 위치에 저장되므로 cach miss 발생 가능성이 높음
'⚙️ CS > 운영체제' 카테고리의 다른 글
| [운영체제] 가상 메모리 & 페이징 & 세그멘테이션 (1) | 2025.05.06 |
|---|---|
| [운영체제] 메모리 할당 방식 (1) | 2025.04.30 |
| [운영체제] Thread Pool & Fork-Join (0) | 2025.04.29 |
| [운영체제] 데드락 (Deadlock) (0) | 2025.04.29 |